Before formal publication in a journal, articles are traditionally peer reviewed. Usually a journal will only publish an article once the editors are satisfied that the authors have addressed any concerns which may have arisen from the review process.
We are aware that this process can take some time, and that not all disciplines publish all outputs in journals. Luckily, researchers are able to make their outputs available by uploading to a preprint server, which in turn can update their ORCID record if that preprint server is an ORCID member. The basic workflow is as follows:
- The author submits an article submission to the preprint server
- The preprint server service collects the authenticated author’s ORCID iD and requests permission to interact with their record, and stores that permission.
- When the preprint is accepted to the server the provider:
- Includes the ORCID iDs in it’s own metadata, and any DOI metadata.
- Add the preprint to the author’s ORCID record, including the preprint ID (e.g a DOI) and using the preprint work type with the relationship “Self”. This connects the person with the preprint.
- Display the authenticated iD logo alongside the preprint author name and link it to their ORCID record.
- The service also allows the collection of authenticated iDs for any co-authors by emailing them and asking them to authenticate and confirm their contribution.
If the article is accepted for publication in a peer reviewed journal at a later date, the publisher can add the peer reviewed journal article to the ORCID record, and include 2 identifiers: the DOI for the journal article with the relation ‘Self’ and the DOI or work-identifier of the original preprint with the relation ‘Version of’ if they know it. This will group the versions together in the ORCID record, which is helpful for the researcher and others viewing the record.
Example

Linking preprints with peer reviewed or other versions
ORCID supports multiple external identifier relationship types:
- Self: the identifier refers solely to that work and can be grouped with other works that have the same identifier. Example is a DOI
- Part of: the work is part of this identifier and cannot be grouped with other works. Example is an ISSN
- Version of: these identifiers apply to alternate versions of the work and can be grouped with self and version of identifiers. Used to relate multiple versions of a dataset together, or to group preprints with the published version of a paper.
- Funded by: These identifiers are used to link funding to the research output. These identifiers are not used in grouping.
The relationships types are used for grouping works within the users ORCID records. The same work can be added to an ORCID record from different sources; these multiple connections make the information on the ORCID record more authoritative. Where these works have a common identifier (such as a DOI, ISBN, etc.), they are automatically grouped together as they represent the same item. Note that some identifiers are case sensitive and what appears to be two versions of the same identifier (e.g. “11abC” and “11ABC”) will not group, while some are case insensitive and will still group even if the cases are different (e.g. “10.125/1xyZ” and “10.125/1XYZ”). If a work does not have an identifier, it cannot be grouped.
Benefits
We are aware that things are never this simple. The ORCID iDs and permissions potentially would need to be moved from the submission system to a production system, and there may not even be a system in place that authors interact with.
We still think it’s worth doing. ORCID can help streamline the publishing process, improve the management of author and reviewer databases, and enhance the accuracy of name-based repository searches.
Publishers use ORCID to clearly link authors and reviewers—and all their name variants—with their research work, by embedding ORCID iDs into their publication metadata and displaying them on finished publications. By including validated iDs in your metadata you can free researchers from having to manually update their ORCID records, help speed the communication of research works, and reduce the risk of errors. You can also use data from the ORCID record such as researchers’ names, education history, and current affiliations to populate profiles in your own system to save your users time and reduce errors.
Researchers are at the heart of everything that scholarly and research publishers do. Accurate author and reviewer information is vital to indexing, search and discovery, publication tracking, funding and resource use attribution, and supporting peer review.
More information
Items (works, employment, funding, peer review etc) can be added to an ORCID record either manually or using the ORCID member API. If you are an individual looking to update your record check out our help section on this here. If you are a member looking to add items to an ORCID record, you will need the following:
- The researchers permission
- Member API credentials
- And either:
- A vendor system that integrates with the ORCID Member API
- Your own system that integrates with the ORCID Member API
For a complete guide for members using the API to items to a record check out our API tutorial link below:
To support the social component we offer a toolkit of Outreach Resources to help you develop a campaign to support your integration, and communicate to your researchers:
- What ORCID is.
- Why your system collects iDs and how your system will perform tasks, such as updating their records.
- Why your researchers will benefit by creating an ORCID iD and connecting their iDs to your system.
- How ORCID benefits the wider, global research community.
We will be continually building out this “library” of resources based on feedback from the community. If you have an idea for something you might like to see, please feel free to contact us.
Integrating ORCID into your system allows your organization to collect authenticated ORCID iDs and add them to your own data. At the same time, the researcher provides the organization permission to read and write to and from their ORCID record.
To make this work, organizations MUST obtain authenticated ORCID iDs using the ORCID OAuth API. This means they include an ORCID branded button or link within their system, that when clicked, asks the user to sign in to their ORCID record.
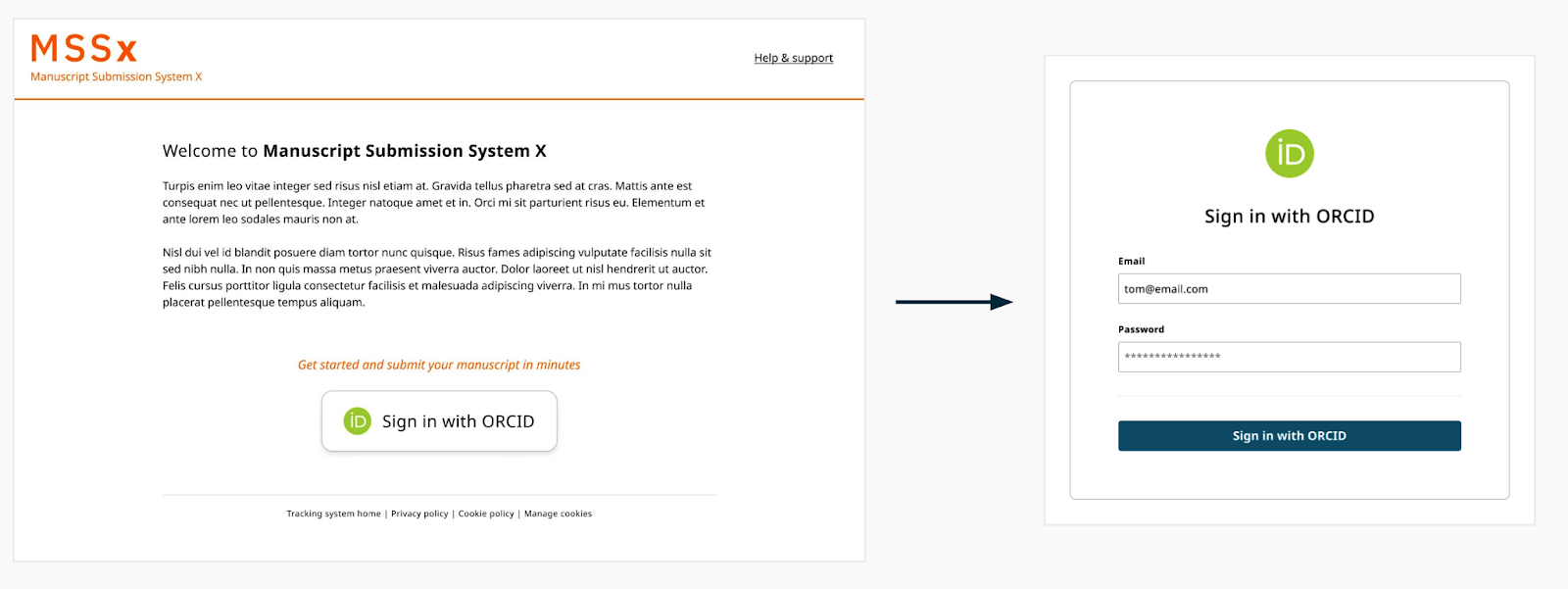
Once signed in, the user will be asked to authorize access to the system asking for their ORCID iD
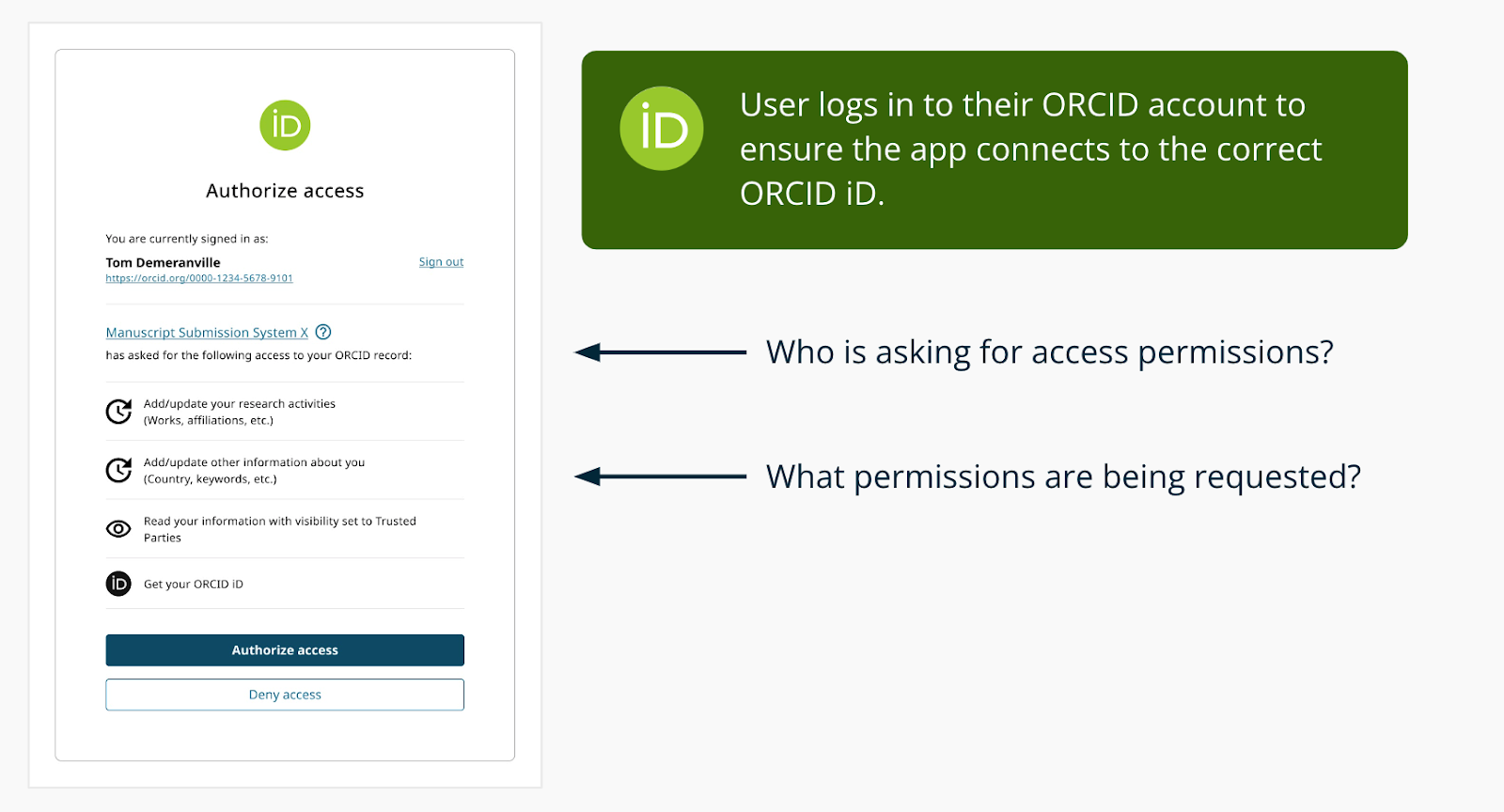
The user’s ORCID iD and name on the ORCID record (depending on visibility settings) is returned to the organization as part of this process. The system can then request additional data from the ORCID API.
The above described workflow for collecting authenticated APIs is available in both ORCID’s public and member APIs. The former is available for use free of charge by non-commercial services.
The process to get permission to add or update data on a user‚s ORCID record uses OAuth, as described in our 3 Legged OAuth FAQ. Only ORCID members can use the Member API to ask for update permissions. In simple terms it works like this:
- Your local system creates a special link
- When clicked, the user is sent to ORCID, signs in and grants permission
- ORCID sends the user back to your system with an ‘authorization code’
- Your system exchanges that code for an ‘access token’
- The access token lets you update the user’s record
ORCID strives to enable transparent and trustworthy connections between researchers, their contributions, and their affiliations by providing a unique, persistent identifier for individuals to use as they engage in research, scholarship, and innovation activities. Ensuring that the correct ORCID iD is associated with the right researcher is a critical step in building the trustworthiness of the ORCID dataset and the broader scholarly communications ecosystem. For this reason, ORCID does not permit the manual collection or entry of ORCID IDs in any workflow where it is possible to collect ORCID IDs directly from record holders themselves.
Researchers can easily and securely share their ORCID iDs with the systems they interact with, which proves they own their ORCID iD. Those systems can then share information about researcher activities with other systems, which creates a chain of validated and trusted assertions about researcher activity. The end result is that the correct person is associated with the correct activities across a broad range of scholarly information workflows.
For more information see: https://info.orcid.org/collecting-and-sharing-orcid-ids/
I have developed my integration using the Sandbox, how do I get Production Member API credentials?
Member organizations request ORCID Member API credentials on the production (live) server by completing the Production Member API client application form. Before issuing production Member API credentials, the ORCID Engagement team/Consortia Lead will review a demo of your integration in the ORCID sandbox. This gives us a chance to see the great integrations you have built and offer workflow improvements, as well as check that all integrations meet our best practices and minimal requirements for launch.
To provide a demo of your system you’ll need to set up a working integration with the ORCID sandbox that the ORCID team can preview. There are a few ways to share your working sandbox integration:
- Recommended: Live demo: Contact us to schedule a live demonstration. We’ll provide meeting software that allows you to share your screen for you to demo your integration.
- Test site: If your development site is public, send us the URL along with test credentials (if needed) to access your system and instructions describing how to use your system’s ORCID features. Provide additional documentation to verify what we would not be able to see from the user end, e.g. API version used, what data is stored by your system, etc.
- Screencast or screenshots :Send a recording or a set of screenshots with descriptions clearly explaining and demonstrating how your integration works at each step, including what happens if a user denies access or disconnects their iD. Be sure to provide additional documentation to verify anything we would not be able to see from the user end, such as API version used and how data is stored
Technical documentation
A more detailed tutorial can be found here.