The European Organization for Nuclear Research—CERN—is a host laboratory to the largest scientific collaborations for high-energy physics researchers. It’s also one of the highest data contributors to ORCID, with over 1.9M trust markers added since 2013. CERN is one of six institutional partners in the INSPIRE information platform (together with DESY, Fermilab, IN2P3, IHEP and SLAC), which has 25,000 daily users and 100,000 author profiles that connect with over one million articles and preprints relevant for their research.
For almost 50 years, INSPIRE HEP has been the main information hub for the high-energy physics community that helps researchers share and find accurate scholarly information. In turn, INSPIRE HEP is integrated with ORCID with an OAuth sign-on that serves several purposes for researchers who use CERN and other facilities in high-energy physics research.
The following interview is with Micha Moskovic, the INSPIRE Product Manager.
What are the main reasons for INSPIRE adopting ORCID?
When an author wants to make changes related to their INSPIRE author profile—such as submit a new paper or change anything on their profile in INSPIRE—they have to log into INSPIRE to submit content. This is in part to control Spam.
In 2018, INSPIRE HEP built an integration with ORCID in order to design useful services for high energy physics researchers. We use the ORCID OAuth sign-on, which requires users to have an ORCID record instead of us having local accounts with them. This allows us to know exactly who they are. It has an added benefit of promoting ORCID in the high-energy physics community because they are required to have an ORCID to submit content to INSPIRE or make modifications.
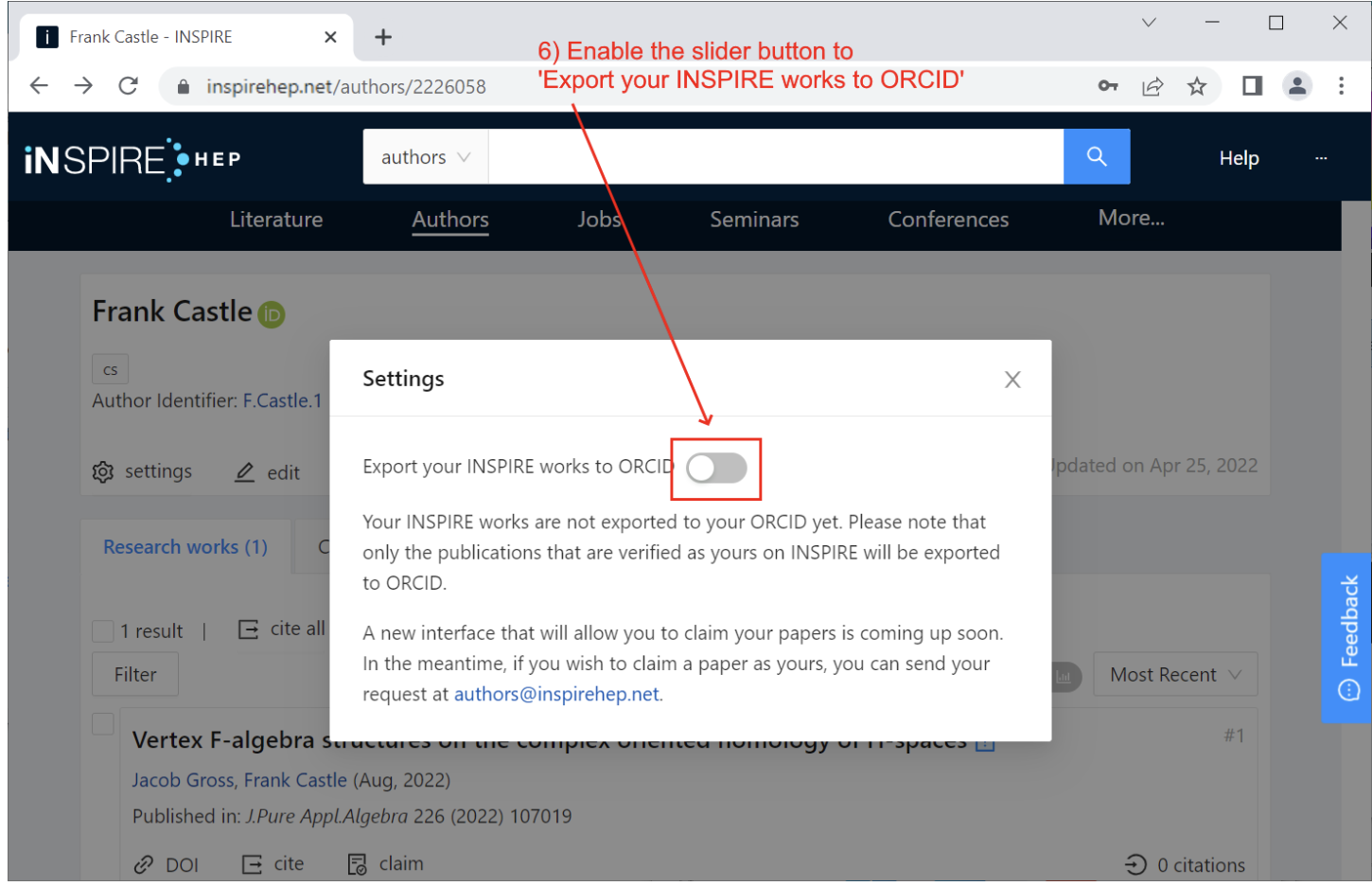
Additionally, we designed the integration to make it easy for researchers using INSPIRE HEP to populate their ORCID records. If the researcher gives us permission, then we will export all the works they have in INSPIRE to their ORCID record.
Increasingly, people are required to have their ORCID profile populated with information on their papers, so it’s good for our users to have an easy way to populate that information. INSPIRE hosts very large collaborations with thousands of people on it. The research papers have thousands of authors on them, so it would be unrealistic to report all of this manually.
We could have done many other services that have local logins, but because we want to incentivize the community to do the right thing, we want to have only the ORCID login.
INSPIRE’s integration with ORCID was implemented in 2013. Has anything changed over time?
Originally, we had just a single export of data from INSPIRE to ORCID users who had given us permission to add data to their records. When there was a new paper, we added it to their records, but it was just a one-time thing. So for every paper, if it had already been exported, then that was it and it was never exported again.
Then in 2018, we decided to have a different system where instead of having just the initial version exported, we continuously update the work, so that required some changes on our side.
The main reason for doing so is that we don’t have separate records for different versions of papers, but we have a single combined record for a preprint, which is very common in our field, and the published version. So if we just sent the initial version to ORCID when we created the record, it would often be a preprint and not a publication. The way we do it now is to reflect the latest version of records in INSPIRE.
What technical or communications challenges did you face along the way? How did you overcome them?
We had some challenges with the data volume. At first we were sending every update to ORCID, which was way too much. I don’t know if we actually did that or if we planned to do it that way. We realized that was not going to work out because we would spam ORCID.
So we built something to determine whether the update on our record is relevant for ORCID because we have lots of metadata. If, say, a reference changes because we discover a new paper and we have a reference that will be linked to another paper, that’s a change from our perspective. But that’s not necessarily a meaningful change for ORCID. So now for every update on the INSPIRE side, we compute what it would look like in the ORCID version of the metadata, and we compare that with what we already sent. If that won’t change, then we won’t send the update to ORCID because it’s a change that is meaningful for INSPIRE, but not for ORCID.
How are your researchers benefitting from your contributing data to their records?
INSPIRE is a service for anyone in the world who is using it in the global high-energy physics community. They are benefitting because they can very easily have their ORCID record fully complete with all their works including things that are not published. With a typical integration they would not get their preprint added because they only add published papers. For research assessment purposes, authors have to provide their ORCID record, and this is tedious to do manually if you have hundreds of papers. Each paper can have thousands of co-authors. So providing this feature is very helpful because on the INSPIRE side, researchers just have to make sure their profile is clean and complete and then tick a box to export to ORCID and it will happen automatically.
How is the institution utilizing trust markers in your workflows?
We don’t particularly rely on trust markers in our workflows the way other institutions might, as our goal is to build services that are useful to our end users, as opposed to utilizing records for any kind of assessment checks. However, we strongly encourage participants to get an ORCID record. And of course because we add the trusted data that we hold about our users to their records, that data is accompanied by a trust marker that can be reused in a number of different workflows..
How has ORCID adoption grown at your institution? What activities have been most successful in fostering adoption?
At CERN, ORCID adoption has grown because we have made efforts to get ORCID in a central place for the large experiments. Also, the new CERN account system has a field for registering ORCIDs, which our previous system didn’t have. And now when people register for a CERN account, we ask them for their ORCID.
Do you have any recommendations you would like to share with other research institutions or organizations that are planning to adopt ORCID?
At INSPIRE we have the same problem as others in the research world. We see a lot of papers, and there are authors on them, but the name and affiliation alone doesn’t tell you who the person is. Likewise, there are the same names that show up. ORCID solves this problem in a very good way through disambiguation, which is really a hard problem to solve without ORCID.
In an ideal world, everyone would have an ORCID because it’s a great tool for disambiguation and other things institutions typically care about, like knowing what research was done there. ORCID is definitely a part of solving the problems of identifying researchers and their outputs, and it is worthwhile to figure out what type of integration will be best for the institution.
Top data contributors add value to the research ecosystem
In a healthy research ecosystem, anyone, anywhere should be able to correctly identify a researcher in connection to their publications, grants, and affiliations. Every institution involved in research bears part of the responsibility of strengthening their corner of the research ecosystem to ensure this possibility. By sheer volume alone, CERN, through the robust INSPIRE platform, is an example for how facilities can utilize ORCID to fulfill their own institutional requirements while also contributing rich metadata to ORCID records that can be propagated throughout the scholarly infrastructure. Like CERN and INSPIRE, ORCID member organizations can offer value to their community by requiring ORCID through a single sign-on integration.
Learn more about trust markers and their importance in the blog Trust Markers: Interpreting the trustworthiness of an ORCID record. Numerous case studies can also be found on the ORCID blog search results for Trust Markers.
Contributor
Dr. Micha Moskovic

Dr. Micha Moskovic obtained a Ph.D. in Theoretical High Energy Physics from the Université Libre de Bruxelles (Brussels, Belgium) in 2014. He was a postdoctoral researcher in the String Theory Group of the Università di Torino and INFN, Torino (Turin, Italy) between 2014 and 2016. Since 2016, he has been a member of the CERN Scientific Information Service (Geneva, Switzerland) as an expert on INSPIRE content and metadata and has been involved in the development of the new INSPIRE platform. In 2019, he became the new INSPIRE Content and Community manager. He has been the INSPIRE Product Manager since 2022.
