Five Years of the ORCID Trust Program
2021 is the fifth anniversary of ORCID’s Trust Program, and we’re celebrating with a series of blog posts that outline our thinking about how we balance the sometimes-competing priorities of researcher control and data quality, while adhering to our values of openness, trust, and inclusivity.
In this blog post, our second in the Five Years of the ORCID Trust Program series, we introduce the concept of “trust markers” in an ORCID record and outline how users of ORCID data can determine for themselves which kinds of data in an ORCID record they consider to be trust markers for their specific use case.
Assertions, trust markers, and ORCID’s model of distributed trust
ORCID’s foundational commitment to researcher control has proven essential to winning the trust and participation of researchers, which in turn has been largely responsible for the wide uptake and utilization of ORCID by organizations across the globe. However, ORCID is like most other high-traffic sites which allow user-generated content; we can be an attractive target for those creating fake or deceptive records in an attempt to game search engine algorithms or to falsely claim credit for the work of others.
We talked more about how we’re handling these situations in our previous post, but how can users of ORCID data determine for themselves which ORCID data to trust for their specific use case?
ORCID enables connections between researchers (via their ORCID iD) and their activities and affiliations (via other identifiers and APIs), which are asserted — either by the researcher, or with their permission, by ORCID members.
As we mentioned in our previous blog post, ORCID utilizes a distributed trust model in order to balance the sometimes-competing priorities of researcher control and data quality. Reliable, trustworthy data sources can be connected via authenticated workflows to an ORCID account — with the record holder’s permission — to assert data into an ORCID record. By recording and transparently disclosing the provenance of each and every assertion present in a record, we provide a mechanism for users of ORCID data to judge the veracity and trustworthiness of information in ORCID records for themselves.
This mechanism, the recorded and disclosed provenance of assertions, leads to what we call “trust markers.” The assertions in records that you trust, for your particular use case, should be those added by the data sources you trust, as disclosed by the provenance data attached to each assertion.
Using trust markers to interpret data in ORCID records
Let’s take a look at some of the trust markers that can be found in the Affiliations, Works, Other data, and Last activity sections of an ORCID record.
Affiliations
An affiliation is a relationship between a person and an organization, linking the two. Record owners can add affiliations manually to their own records using our user interface; however, trustworthiness is increased when ORCID member organizations add their own affiliations to ORCID records. By adding affiliation assertions to ORCID records, member organizations are vouching for the fact that the record holder is (or was) indeed affiliated with the organization.
Currently there are nearly 4.2 million records with an affiliation (33.5%) in ORCID, with member organizations having added about 9% of them.
The screenshot below shows affiliation data (in this case, Employment) that has been asserted by this record holder’s employer (of course with the record holder’s permission). We know this because the Source of the assertion is the Massachusetts Institute of Technology, meaning this bit of data has been added to the record by MIT using an authenticated workflow.
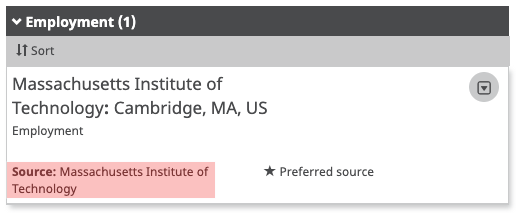
A key priority for us at ORCID is to make it easier for institutions to add affiliations to the ORCID records of their researchers. Traditionally, ORCID member organizations have integrated one or more internal systems with the ORCID API in order to add trusted affiliations, however, we know that it is often difficult for institutions to prioritize getting this work done. Our new Affiliation Manager tool, launched in May and available to all Consortia members, makes it easy to add affiliation data to ORCID records by simply uploading a CSV file without the need for any technical integration.
Whether using the traditional API mechanism or the Affiliation Manager, the ORCID record holder is always asked to give explicit permission to a member organization before data is added to their record, thus we allow authoritative data to be included in ORCID without sacrificing our principle that researchers are fully in control of their own records. And because organizations have to be members of ORCID before they can add assertions, signing our membership agreement and using API credentials that we provide, users of ORCID data can be sure that the third-party assertions have indeed been made by the organizations indicated in the provenance data.
Though assertions made by trustworthy member organizations are the most powerful trust markers you will find in an ORCID record, a lot of valid records have self-asserted employment or educational data for a few reasons:
- Many records were populated with affiliation data by early adopters of ORCID before a lot of organizations had a chance to integrate with ORCID.
- The affiliation data is historic, in other words, it is data about affiliations that occurred before ORCID even existed.
- The record holder may be affiliated with an organization that isn’t yet a member.
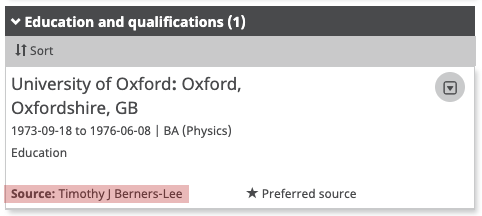
In the case that an affiliation assertion was made by the record holder, their name will be the Source, such as in the screenshot below.
Works
The Works section of an ORCID record contains research outputs, such as publications, data sets, and conference presentations. This is where a bulk of the “trust markers” are located, as 80% of Works are added by member organizations, typically publishers, institutional repositories, data repositories, and abstracting & indexing databases (e.g., Web of Science, Scopus, etc).
Some members push work data into ORCID records (with permission given by the record holder) using our API; others create Search & Link import tools which allow record holders to pull works into their record from preferred sources on demand. And we also have integrations with our fellow scholarly infrastructure providers, Crossref and DataCite, which allow ORCID records to be automatically updated when articles are published by Crossref member publishers or datasets added to DataCite member repositories.
If you’ve ever published an article that’s been assigned a Crossref or Datacite DOI by the publisher, look out for the notification asking you for permission — grant permission and future works with Crossref or Datacite DOIs will be automatically added to your record. We’ll share more information about this, and other ways you can ensure your ORCID record can be automatically updated, in our next and final blog post of the series.
In exactly the same way as affiliations, the source of each work item in an ORCID record is clearly indicated in the ORCID UI (and also in our API responses), as shown in these screenshots. Numbered items correspond with the questions to consider below:

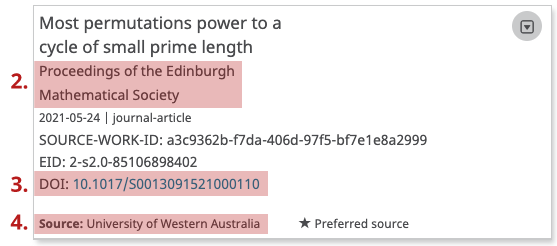
Questions to consider when assessing how trustworthy a record is from the Works section include:
- How many works are connected? (For someone who is a late-career researcher, you might expect to find a higher number of works.)
- What is the publication?
- Is the link to the persistent identifier (often a DOI, as is seen above) resolvable?
- What’s the source of the record? This one shows the source is third-party and populated via an authenticated workflow.
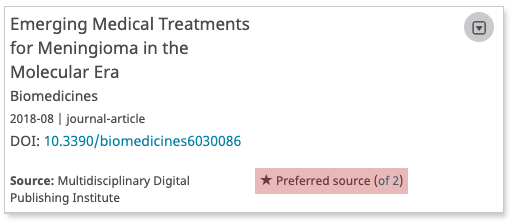
Note, “Preferred source” (highlighted above) denotes the version of an activity (e.g., Employment, Works, etc.) that is considered the definitive one. When there are several variations of a particular work from different sources, the record holder can select which variant is the definitive one — the Preferred source.
Other data
Located on the left-hand side and top of the record, the Other data section of ORCID records contains fields, such as Other IDs, Websites & Social Links, Biographies, that can be used to cross check against corresponding records in other data sources or websites you trust to determine the trustworthiness of ORCID records. Note that Other IDs refer to person IDs issued by other systems and can only be added to records by ORCID member organizations using authenticated workflows; expanding the section reveals the provenance information.

Last activity
Located at the bottom of the record, this data shows when the record was last updated by the record holder or by one of their trusted institutions and is visible whether or not the rest of the record is private. The more recent the date, the higher the probability that the record is actively updated and maintained.

As with any online system that houses user-generated data, users of ORCID data should make their own evaluation of the validity of a record’s contents, bearing in mind their own use case and their tolerance for inaccurate data. We hope this post has explained how the trust markers we have described can be used to make those judgments and understand the source of each and every piece of data present in an ORCID record.
Data-sparse records can still be valid and usable
It’s important to bear in mind that the absence of some or all of the trust markers we’ve outlined does not in itself indicate that a record is problematic. A valid record with usable data might not contain all of the trust markers mentioned or indeed may consist entirely of self-asserted data. The vast majority of ORCID record holders act in good faith, and as the public data in ORCID records is held open to public scrutiny, lay themselves open to criticism by their peers and the broader scholarly community if they make false claims.
Similarly, a data-sparse record that was last updated in 2016 could simply mean that the record holder hasn’t logged into their record since they registered for an ORCID iD. Remember that the primary use case for ORCID, to be a mechanism by which researchers are disambiguated from other researchers, doesn’t require any metadata other than the ORCID iD itself. By simply collecting ORCID iDs using authenticated workflows, which can be done by anyone using our public API, users of ORCID data can be reasonably confident that the person asserting an iD is in fact the record holder which is all that is needed in many use cases.
Of course, abandoned or forgotten accounts are hardly unique to ORCID. An analysis of data from more than 20,000 users by Dashlane in 2015 found that the average user has 90 online accounts, and in the U.S., there are an average of 130 accounts assigned to a single email address. We can only imagine that number is a lot higher today.
In our case, the support we’ve received from so many publishers and funders in mandating ORCID sometimes has the unintended side effect of causing researchers to create ORCID records simply to get through the manuscript submission process or apply for funding, rather than because they intend to use and maintain the ORCID record going forward.
To this end, we are focusing efforts on increasing the value of ORCID to researchers and helping them better understand not only the usefulness of their records but also how to reduce the effort required to maintain them. We’ll talk more about this in our third blog post, but first let’s briefly discuss some UI improvements we have on our roadmap.
Making trust markers easier to read: Ongoing improvements to the ORCID record UI
The user interface for the ORCID record is the most visible touchpoint for our users and the very start of their journey towards trust in ORCID. Regardless of how adept our users become at interpreting trust markers in the ORCID record, we will always be working to improve our user interface and workflow to create a delightful experience for record holders and improve incentives for using the record and keeping it up to date.
As part of our continual improvements, we are redesigning the registry’s user interface and experience from the ground up with greater emphasis on creating a clear, legible layout without sacrificing information density. Our goal is to make each item, affiliation, work, or other record element easily readable with quick access to the metadata in a simple format that is a delight for users to work with. After the release of these improvements, we will be shifting our UX work focus to accentuating trust markers in the ORCID record.
Up next: Getting the most out of your ORCID record
In our first blog post in this series, Balancing Researcher Control and Data Quality, we reacquainted users with our Trust Program to clarify our thinking about how we balance the sometimes-competing priorities of researcher control and data quality, while adhering to our values of openness, trust, and inclusivity.
In our last blog post in the series, we will talk more about how researchers can get the most out of their ORCID record, and how member organizations can encourage their researchers to do so. For example, what are the five things you could do in the next five minutes that would ensure your record was not only up to date, but was automatically kept up to date in the future? Stay tuned!


