[avatar user=”Gabriela Mejias” size=”thumbnail” align=”left” /]
In this installment of ORCID Success Stories, EMEA Manager Gabriela Mejias discusses the ORCID/Zurich Open Repository and Archive (ZORA) integration with Martin Brändle (IT specialist for ZORA) and André Hoffmann (long-term archiving for ZORA).
Q. Can you briefly describe the ZORA integration?
A. ZORA is the primary directory of publications by researchers at the UZH and provides access to the full texts. Its focus is on qualified scientific publications. The repository, which is based on EPrints software, is operated by the Data Services and Open Access team of the Main Library together with an IT team at IT Services of the UZH.
Improving author findability, access, and citation statistics
Q. Thinking back to a year or so before University of Zurich joined ORCID, what were the main reasons for you becoming a member?
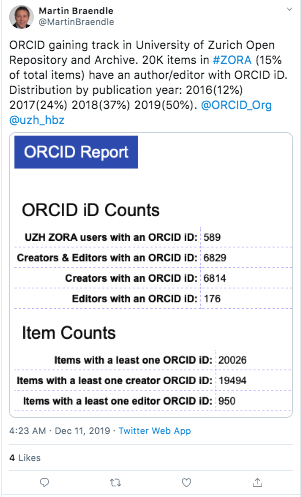 A. In 2013, the teams mentioned above were already in loose contact with ORCID and were following early implementations by other institutions. One idea was to implement ORCID centrally within the UZH Identity and Access Management (IAM) and to connect it with a user self-registered UZH ID, a project that should enhance the IAM. However, the self-registration project never came to life and hence it was decided to focus on ORCID integration in ZORA, because it has a comprehensive publication, author and user registry of active and former members of the UZH and offers interfaces to other systems.
A. In 2013, the teams mentioned above were already in loose contact with ORCID and were following early implementations by other institutions. One idea was to implement ORCID centrally within the UZH Identity and Access Management (IAM) and to connect it with a user self-registered UZH ID, a project that should enhance the IAM. However, the self-registration project never came to life and hence it was decided to focus on ORCID integration in ZORA, because it has a comprehensive publication, author and user registry of active and former members of the UZH and offers interfaces to other systems.
One of the challenges we had back in 2016 when we began conceptual design was managing 80,000 publications by 280,000 authors with 100,000 distinct names. Additionally, many author entries had slight variations in their names which hampered author findability, access, and citation statistics. The variations also impacted the publication lists served by ZORA on the UZH website and interoperability with other systems such as the academic report of UZH.
Based on what we knew, we felt that the implementation of ORCID in the data model and workflow of ZORA would support the search, submission, review, and data cleaning processes.
Q. What were your top priorities once you’d joined ORCID?
A. We had three main priorities:
- First, to provide a large amount of ORCID-tagged publications. To do so, all import and export interfaces and formats (e.g. Crossref, PubMed, DataCite Metadata Schema and further) were evaluated for their suitability for ORCID.
- Secondly, we wanted to reduce typos and variations in author names, and
- Finally, to raise interest for and visibility of ORCID with future users.
Therefore, implementation was done in three phases:
- Phase 1 included setting up the data structure and the Create or Connect your ORCID iD functionality
- Phase 2 implemented all procedures in the submission and review workflow plus the import and export plugins for ORCID and other data sources
- Phase 3 added the publication tagging function for authors and submitters
Developments such as export to the academic report, an ORCID coverage report and an author authority table to track inconsistencies in names and publications were postponed after ZORA went public with its ORCID integration in November 2018.
Q. What were the biggest challenges when you started to implement ORCID at University of Zurich, and how did they impact your plans?
A. Challenges were faced both on the organizational as well as on the technical side. As a basic member we have basic ORCID functionality. At the time of conception, the ORCID plugin provided by EPrints Service was still in its infancy. Therefore, we implemented a custom ORCID integration.
Another challenge was the internal distribution of the submission process at ZORA across diverse roles. The different roles are user, submitter, editor and admin. Permissions to interact with user’s ORCID iDs are collected with the ORCID Member API, and delegated roles can trigger the import and export of publications data to ORCID records. Since a repository should reflect its publications as closely as possible, we wanted to include iDs from external co-authors that we import from Crossref or PubMed. In all cases, the source of the ORCID iD (ZORA user authenticated ORCID iD or external co-author iD ingested via Crossref or PubMed) is displayed in the publication page.
Another challenge was setting up the communication strategy which had to be compliant both with requirements by ORCID and our data protection attorney. This necessitated close collaboration with and training of the Open Access team. The voluntary nature of researcher participation in ORCID, in line with the recommendations of the ORCID-DE privacy report, was emphasized.
In its initial phase, the communication strategy focused both on general aspects and benefits of ORCID as well as on practical step-by-step instructions for using ORCID in ZORA. Furthermore, how can continuous awareness of ORCID be maintained in an organization that is per se fluctuating? For this, we set up a specialized “ORCID information phase” in our software planning and bug tracking system in order to collect ideas and monitor development of ORCID coverage at UZH.
Personal contact means increased participation
 Q. What kind of outreach, communication, and education did you do for users at your organization before, during, and after launching ORCID? What worked, what didn’t?
Q. What kind of outreach, communication, and education did you do for users at your organization before, during, and after launching ORCID? What worked, what didn’t?
A. During the concept phase, we evaluated the Create (institution creates ORCID records on behalf of its members) and the Encourage model (institution encourages members to self-register with ORCID). By recommendation of UZH’s data protection attorney, we decided to pursue the Encourage Model, although it meant the number of UZH members having an ORCID iD would be considerably lower.
A few months before launch, initiatives such as a lunch break lecture by IT Services or a PhD information literacy course by the Main Library were used to stimulate interest in ORCID. When we launched ORCID we provided How to/FAQs/video tutorials on the Main Library’s website, blogs by both Main Library and IT Services of UZH and internal emails to all research staff.
Ongoing awareness is now being built using coffee and lunch break lectures, awareness campaigns on info screens, handouts for departments and libraries to explain necessary steps and workflows, and information literacy courses. We tracked the number of new ORCID iDs before and after the outreach efforts. There was a significant increase, especially after we personally contacted researchers and administrative staff.
Vertical and horizontal support is critical for successful integrations
Q. What impact has your ORCID integration had internally?
A. ORCID iDs are especially useful for the quality assurance of the repository information, and they ease the creation of precise publication lists. For the library, ORCID as a topic is an excellent tool for getting into contact with researchers and institutes and to foster exchange in both directions: on the one hand, by providing support, training and instruction on the difficult topic of author identification and search, on the other hand by getting valuable feedback on its services.
Q. What do you think would be valuable for other members to know about integrating with ORCID in repositories?
A. We think that obtaining support both vertically and horizontally is paramount for a successful integration. Vertically, at UZH this started by getting formal support by the university board, the library board and within IT Services for the project. This was further simplified by the fact that ZORA is well-known as a key service for visibility of the university’s publications and that it is an important driver for Open Access itself.
Horizontally, it was important to include and inform stakeholders such as the scientific and liaison librarians and the data protection attorney about the purpose and value of ORCID in an early stage of the project. The wealth of resources that ORCID has created in past years for user outreach and for integration of ORCID into repositories is a treasure that should not be neglected during planning and can be used to bring stakeholders together.
