Datasets are an important output and resource for researchers of all disciplines. For the community to effectively access and re-use datasets, an understanding of data storage and attribution is fundamental. From that understanding flows the development and use of standard data exchange protocols. How are ORCID identifers being embedded into data repository workflows? In addition to a number of recent integrations by figshare, ANDS, and ODIN, Dryad is starting work to pilot use of ORCID identifiers in DSpace, discussed at the OAI8 DSpace User Meeting hosted by @mire.
Data storage options
Researchers today have numerous options for storing their data. Some research universities support data management activities, including the publication and archival of data through an institutional data repository; this activity is supplemented by Dryad, which provides open source resources on the DSpace platform to archive data sets associated with research publications integrated into the manuscript submission and review process. National organizations like the Australian National Data Service (ANDS) provide an environment for the publication, archival, discovery, and reuse of research data. Community platforms like figshare make it easier than ever for individuals, scholarly societies, publishers, research institutions, and funding agencies to promote data preservation and reuse, by capturing a wide variety of research objects including figures, tables, spreadsheets, and flat files.
Dataset attribution
It is becoming increasingly possible to manage attribution with the assignment of DOIs to data sets. Each of the organizations mentioned above not only serve as data repositories, but through collaboration with DataCite, they also assign and manage DOIs for research objects. DOIs have been used for the identification and citation of journal publications for about a decade, and the assignment of DOIs for datasets signals the increasing acceptance of research data as an essential—and legitimate—part of the research record. But there is still the challenge of connecting datasets with the people who have created them and who are re-using them.
That’s where ORCID comes in. As dataset DOIs have been growing, so has the number of researchers who are registering for ORCID identifiers. It’s exciting to see these connections growing. As an ORCID launch partner, figshare has been supporting the registration of data depositors since ORCID opened the registry in October 2012. Recently, figshare launched an enhanced ORCID integration that incorporates OAuth authentication and allows users to exchange dataset metadata between figshare and ORCID. Both ANDS and Dryad are also planning to implement ORCID registration and authenticated identifer exchange at the time of dataset deposition.
Interoperability and open source collaboration
ODIN, the ORCID and DataCite Interoperability Network, released a beta version of the DataCite / ORCID Integration Tool, enabling researchers to search DataCite and import metadata from objects with DataCite DOIs to their ORCID record. ODIN is a two-year European Commission-sponsored collaboration involving ORCID EU, DataCite, British Library, CERN, ANDS, Dryad, and Cornell University with the goal of using existing standards to link researchers and datasets. To create this tool, ODIN built on code developed by CrossRef and made available as open source on Github, a collaborative development platform where ORCID open source code is also hosted. The source code for the tool itself is available at https://github.com/mfenner/cr-search. Gudmundur Thorisson, an ORCID EU participant on the ODIN project, provided a demo of the integration tool at ORCID Outreach Meeting, held in Oxford in May 2013. He remarked, “We were able to create a working prototype with less than a week of developer time. This speaks volumes about the advantages of the open source model which is increasingly being used by projects and organizations in this space.”
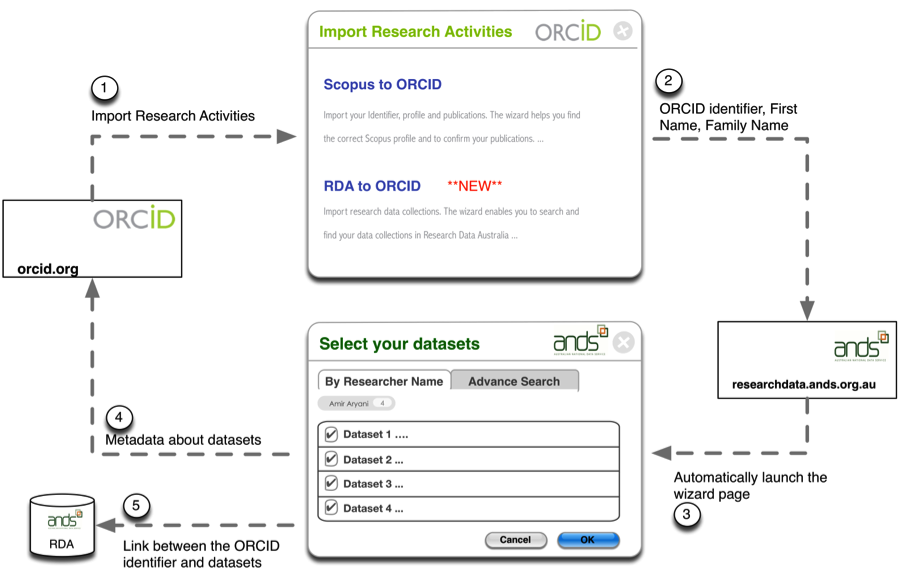
ANDS is in the process of launching an end-to-end system that allows researchers to search the ANDS data repository, import works metadata to ORCID, and also push the ORCID identifier into the ANDS system to become a piece of the metadata associated with a dataset.
Another big opportunity for interoperability and attribution is in DSpace repositories. Dryad is currently developing use cases and a prototype ORCID integration, and will make code samples available via their open source repository. Their plans include associating data set submitters and co-authors with ORCID iDs and exposing these identifiers in the Dryad repository. As Todd Vision, Associate Professor at the University of North Carolina and ORCID Board member, explained at the OAI8 meeting, “Our goal with ORCID identifier integration is to transcend current data silos imposed by institutional identities, manual data entry, and name-string searches.” Dryad use cases include a first pilot for the use of OAuth in the DSpace platform. This work has implications for institutional repositories around the world for attribution and managed access to datasets.
