Ouverture est une clé ORCID Plus-value, et de suivre ce principe et de célébrer Semaine du libre accès, chaque année, nous publions notre fichier de données public annuel. Le dossier 2019, qui est maintenant disponible, contient un instantané de tous ORCID enregistrer les données que les chercheurs avaient marquées publiques dans le ORCID Registre au moment de la création du fichier le 1er octobre 2019. Notre fichier public de données est publié sous un Renonciation CC0 et est libre d'utilisation pour tout le monde - au moment de la rédaction, dossier de l'année dernière avait été visionné plus de 5,000 3,200 fois et téléchargé plus de XNUMX XNUMX fois.
Comme 2019 est ORCIDL'année du chercheur, cette fois nous sommes heureux de partager avec vous deux exemples de chercheurs qui utilisent les données de notre fichier de données public pour leurs recherches.
 Dario Rodighiero (Associé postdoctoral au MIT, Faculté des études comparatives des médias/écriture)
Dario Rodighiero (Associé postdoctoral au MIT, Faculté des études comparatives des médias/écriture)
La Carte mondiale de la recherche est un projet qui analyse la communauté de recherche en termes de relations et de trajectoires individuelles. Il s'appuie sur le ORCID fichier de données public — un bon exemple de la façon dont une organisation à but non lucratif peut aider à rendre la recherche ouverte et 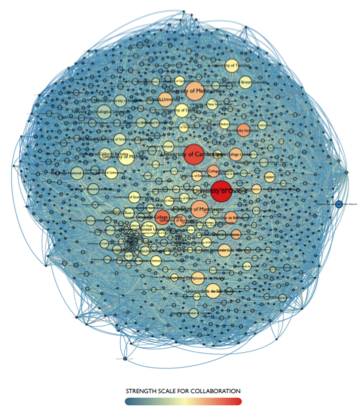 accessible à tous — et aussi ma façon de soutenir le ORCID initiative. Le projet est né de mon thèse de doctorat qui illustre une méthode visuelle pour représenter une faculté de EPFL. Grâce au soutien de la Fonds national suisse de la recherche scientifique, ma recherche a maintenant pris de l'ampleur, passant des membres individuels du corps professoral à l'analyse des institutions et universités mondiales. Mon approche interdisciplinaire me permet d'explorer les ORCID ensemble de données sous deux angles. La première est purement visuelle et se concentre sur la manière dont les individus et les institutions peuvent être correctement et équitablement représentés à l'aide de la conception graphique. Le second concerne le traitement des données, en utilisant les développements récents du traitement du langage naturel et de l'intelligence artificielle pour extraire des informations significatives. L'intersection de ces deux perspectives permet une nouvelle façon de faire de la recherche en réfléchissant à la fois au calcul, à la visualisation et à l'interprétation des données. Ce projet spécifique se concentre sur trois étapes simples : 1) l'étude des collaborations entre les institutions (voir figure ci-dessous), 2) l'analyse des trajectoires individuelles des universitaires à travers les instituts au fil du temps, et 3) la création d'un système de recommandation basé sur données collectées et générées. Je remercie mon superviseur Kurt Fendt, MIT et mes collègues, Ringgold pour m'avoir permis d'utiliser leur base de données, le MétaLab de Harvard pour leur soutien intellectuel, Mauro Martino (IBM) et Paolo Ciuccarelli (Northeastern University) pour leurs conseils, et Abram Turner (MIT) pour l'aide apportée durant son stage.
accessible à tous — et aussi ma façon de soutenir le ORCID initiative. Le projet est né de mon thèse de doctorat qui illustre une méthode visuelle pour représenter une faculté de EPFL. Grâce au soutien de la Fonds national suisse de la recherche scientifique, ma recherche a maintenant pris de l'ampleur, passant des membres individuels du corps professoral à l'analyse des institutions et universités mondiales. Mon approche interdisciplinaire me permet d'explorer les ORCID ensemble de données sous deux angles. La première est purement visuelle et se concentre sur la manière dont les individus et les institutions peuvent être correctement et équitablement représentés à l'aide de la conception graphique. Le second concerne le traitement des données, en utilisant les développements récents du traitement du langage naturel et de l'intelligence artificielle pour extraire des informations significatives. L'intersection de ces deux perspectives permet une nouvelle façon de faire de la recherche en réfléchissant à la fois au calcul, à la visualisation et à l'interprétation des données. Ce projet spécifique se concentre sur trois étapes simples : 1) l'étude des collaborations entre les institutions (voir figure ci-dessous), 2) l'analyse des trajectoires individuelles des universitaires à travers les instituts au fil du temps, et 3) la création d'un système de recommandation basé sur données collectées et générées. Je remercie mon superviseur Kurt Fendt, MIT et mes collègues, Ringgold pour m'avoir permis d'utiliser leur base de données, le MétaLab de Harvard pour leur soutien intellectuel, Mauro Martino (IBM) et Paolo Ciuccarelli (Northeastern University) pour leurs conseils, et Abram Turner (MIT) pour l'aide apportée durant son stage.
 Robert Eyré (Doctorante à l'Université de Bristol, Département de Mathématiques de l'Ingénieur)
Robert Eyré (Doctorante à l'Université de Bristol, Département de Mathématiques de l'Ingénieur)
De tous les cheminements de carrière possibles, les chercheurs universitaires ont peut-être le plus d'opportunités de voyager et de migrer à l'étranger en créant de nouveaux liens de collaboration et de nouvelles relations. Pour étudier leurs migrations, les résultats de recherche des universitaires peuvent être examinés pour former une trajectoire d'affiliations dans le temps. Cependant, cela peut être difficile lorsque les chercheurs partagent le même nom, un problème courant dans les études sur les migrations qui utilisent des données bibliométriques. Pour lutter contre cela, nous pouvons extraire les CV de millions de chercheurs du public ORCID fichier de données public. Cet ensemble de données est plus de 300 fois plus volumineux que la plus grande étude connue par courrier électronique sur la migration scientifique, menée par Franzoni et al. en 2012.
Nous prévoyons d'étendre notre utilisation du ORCID fichier de données public, pour identifier l'effet que certains événements (tels que le Brexit ou la crise de la zone euro) ont eu sur la migration dans la communauté des chercheurs. Nous travaillons sur une méthode pour éviter les irrégularités dans les données, telles qu'une sur-représentation des personnes ayant récemment obtenu leur doctorat et les sur- et sous-représentations des pays individuels. Ceci sera réalisé en créant des modèles de référence aléatoires pour les données observées et en comparant ces modèles à notre réseau temporel observé obtenant valeurs p pour chaque décision de migration possible chaque année. Ces scores permettront d'identifier les années durant lesquelles un nombre anormal de migrations a eu lieu.
Plus sur le ORCID fichier de données public
Si vous souhaitez utiliser notre fichier de données public, vous pouvez le télécharger à partir du ORCID dépôt. Le dossier de cette année est disponible au format XML et est divisé en fichiers séparés pour une gestion plus facile. Un fichier contient le résumé complet des enregistrements pour chaque enregistrement. Le reste des données est divisé en 11 fichiers qui contiennent les activités pour chaque enregistrement, y compris les données de travail complètes.
Nous publions le fichier de données public sous un CC0 1.0 Dédicace au domaine public et l'utilisation des données publiques est conforme à nos Politique de confidentialité. Nous avons créé normes communautaires recommandées pour utiliser le fichier.
Si vous prévoyez ou utilisez déjà le fichier de données public pour votre recherche, veuillez Faites le nous savoir, Nous aimerions recevoir de vos nouvelles!
